
O projeto de pesquisa sofreu algumas alterações no seu objetivo principal e nos objetivos específicos, alem da metodologia a ser utilizada. A base empírica que no pré-projeto estava definida, tambem esta em fase de modificação, não possuindo ainda uma base de textos para investigação. O resumo e o problema não sofreram alterações.
Resumo
Esta pesquisa aborda a aplicação da técnica de Descoberta de Conhecimento em Textos (DCT), com recursos avançados de Processamento de Linguagem Natural (PLN). Seu objetivo é verificar a eficiência do processo de DCT com uso de métodos linguísticos e não só estatísticos. O estudo propõe identificar automaticamente estruturas com potencial de descrever o conhecimento contido no texto, classificá-las morfologicamente, reorganizá-las, para, enfim, executar procedimento de efetiva descoberta de conhecimento.
Identificação do Problema
Estima-se que 80% das informações de uma empresa estão armazenadas em formato textual, informações essas que frequentemente não são percebidas, manipuladas e utilizadas como um potencial produto organizacional das instituições. O volume enorme de dados gerados e a dificuldade de recuperação da informação contida nos textos são os fatores principais para o abandono, com o passar do tempo, do conhecimento registrado em texto.
A descoberta de conhecimento em texto (DCT) surge como uma forma de resolver essa questão, porem o uso de métodos simplesmente quantitativos no pré processamento dos dados gera resultados insatisfatórios devido a inúmeros problemas linguísticos não tratados de forma automática.
Objetivo
O objetivo principal da pesquisa é verificar se o uso de métodos linguísticos no processamento automático de textos em língua natural aumenta a precisão e a eficiência na descoberta de conhecimento
Objetivo específico
Identificar problemas linguísticos de representação do conhecimento, classificando-os em problemas de função (morfológica ou sintática), significação (semântica) ou contextualização (pragmática).
Analisar e propor soluções automáticas, quando possível, para os problemas identificados.
Identificar ferramentas adequadas para resolução dos problemas linguísticos de forma automática.
Propor aplicação das ferramentas disponíveis para o tratamento dos dados em bases de textos na fase de pré-processamento, antes da efetiva mineração.
Comparar o resultado da DCT obtido com técnicas avançadas de Processamento de Linguagem Natural (PLN) em relação ao resultado sem os tratamentos linguísticos.
Método
O método utilizado na pesquisa será o Método de Arquitetura da Informação Aplicada - MAIA. Esse método foi proposto por Ismael Costa em sua dissertação de mestrado orientada pelo Professor Mamede e defendida no final de 2009. Para ter acesso a pesquisa, clique aqui. O método propõe um olhar humanista para sistemas de Informação. Utilizar um método proposto no departamento nessa pesquisa irá auxiliar a trazer uma visão da Ciência da Informação sobre o tema, pois as técnicas de Descoberta de Conhecimento em Textos e Processamento de Linguagem Natural são geralmente abordadas com uma visão da Ciência da Computação.
Base conceitual
Base de conhecimento ligado a Ciência da Informação, Linguística e Processamento de Linguagem Natural.
Base empírica
A base empírica para a investigação ainda não foi definida, porém será uma base de textos em lingua portuguesa.
segunda-feira, 13 de setembro de 2010
quinta-feira, 2 de setembro de 2010
A não neutralidade da ciência em Tomanik
A não neutralidade da Ciência em Tomanik(2004)
Eduardo Tomanik em seu livro “Um olhar no espelho” trata sobre a não neutralidade da ciência e esse tema gera sempre muita discussão entre os cientistas. A ciência não precisa ser neutra para ser considerada um elemento fundamental para o conhecimento sobre os fatos? Quando um cientista propõe uma hipótese e a investiga, sem a neutralidade, essa hipótese não seria sempre confirmada? Os métodos científicos e a analise dos pares não garante a neutralidade da ciência?
A neutralidade pressupõe, do ponto de vista científico, o não envolvimento do cientista com o objeto de sua ciência, o que para Tomanik é impossível. O cientista esta completamente envolvido com sua pesquisa em todos as suas etapas. Vejamos um modelo básico para planejamento de uma pesquisa proposto por Tomanik para os iniciantes na Ciência.
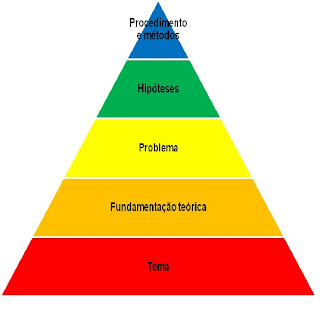
Adaptado de Tomanik(2004)
Eduardo Tomanik ao propor esse modelo, esclarece que não é o único modelo correto, alem de exemplificar durante todo seu livro, que o uso de um manual para todo o tipo de pesquisa pode levar a grandes erros. Porem, vamos nos ater as fases. Na fase do tema, a escolha é do pesquisador ou do seu grupo de pesquisa, ou seja, é uma definição subjetiva, baseada em interesses pessoais.
Fundamentação teórica é a busca por autores científicos que tratam o tema proposto na fase inicial. É nessa fase, segundo Tomanik, que se separa uma pesquisa científica de uma pesquisa baseada no senso comum. Porem, o pesquisador é que escolhe os autores, segundo os seus critérios.
Definição detalhada do problema é uma fase completamente definida pelo pesquisador. Que aspecto desse tema é importante? O que essa pesquisa pretende responder?
A hipótese, que é uma resposta provável e provisória ao problema também é fruto do pesquisador e seu trabalho nas fases anteriores.
Os procedimentos e métodos utilizados dependem da escolha dos objetivos da pesquisa. Apenas quando se sabe o que pesquisar é que se pode definir o como.
Podemos observar que em todas as etapas do planejamento a definição é do pesquisador, e suas escolhas serão baseadas em seus conhecimentos, crenças, necessidades e objetivos. Não é possível pensar em uma neutralidade completa da ciência, pois ela é produzida por cientistas que precisam tomar decisões, fazer escolhas e toda escolha não é neutra.
Porem, o pesquisador não tem liberdade de fazer o que quiser. Se assim fosse, não existiria uma continuidade do conhecimento. Não seria possível aproveitar de um trabalho anterior, pois esse conhecimento seria fruto apenas de uma pessoa e serviria apenas para o seu mundo. O processo de conhecimento é sobre algo(objeto) e visa ser aproveitado. Sendo assim a descrição do objeto, mesmo que seja totalmente subjetiva, precisa ser clara e o mais próxima da realidade. Quais aspectos foram considerados e quais não foram considerados? Quais cientistas também tem a mesma visão sobre esse fenômeno? E quais observam de forma diferente? A base teórica, os objetivos, o pesquisador, a época e outras variáveis precisam ser claras para compreender a base empírica e as conclusões de um trabalho científico.
A não neutralidade da ciência colocada por Tomanik não diminui a sua importância na aquisição do conhecimento sobre a realidade, apenas nos demonstra que não podemos considerar apenas esse conhecimento como verdade absoluta. Todo conhecimento produzido tem seus limites e seus campos de observação, compreender esses limites faz parte do processo de compreensão e produção do conhecimento científico.
TOMANIK, Eduardo Augusto. O olhar no espelho: “conversas” sobre a pesquisa em Ciências Sociais. Maringá: Eduem, 2004.
Eduardo Tomanik em seu livro “Um olhar no espelho” trata sobre a não neutralidade da ciência e esse tema gera sempre muita discussão entre os cientistas. A ciência não precisa ser neutra para ser considerada um elemento fundamental para o conhecimento sobre os fatos? Quando um cientista propõe uma hipótese e a investiga, sem a neutralidade, essa hipótese não seria sempre confirmada? Os métodos científicos e a analise dos pares não garante a neutralidade da ciência?
A neutralidade pressupõe, do ponto de vista científico, o não envolvimento do cientista com o objeto de sua ciência, o que para Tomanik é impossível. O cientista esta completamente envolvido com sua pesquisa em todos as suas etapas. Vejamos um modelo básico para planejamento de uma pesquisa proposto por Tomanik para os iniciantes na Ciência.

Adaptado de Tomanik(2004)
Eduardo Tomanik ao propor esse modelo, esclarece que não é o único modelo correto, alem de exemplificar durante todo seu livro, que o uso de um manual para todo o tipo de pesquisa pode levar a grandes erros. Porem, vamos nos ater as fases. Na fase do tema, a escolha é do pesquisador ou do seu grupo de pesquisa, ou seja, é uma definição subjetiva, baseada em interesses pessoais.
Fundamentação teórica é a busca por autores científicos que tratam o tema proposto na fase inicial. É nessa fase, segundo Tomanik, que se separa uma pesquisa científica de uma pesquisa baseada no senso comum. Porem, o pesquisador é que escolhe os autores, segundo os seus critérios.
Definição detalhada do problema é uma fase completamente definida pelo pesquisador. Que aspecto desse tema é importante? O que essa pesquisa pretende responder?
A hipótese, que é uma resposta provável e provisória ao problema também é fruto do pesquisador e seu trabalho nas fases anteriores.
Os procedimentos e métodos utilizados dependem da escolha dos objetivos da pesquisa. Apenas quando se sabe o que pesquisar é que se pode definir o como.
Podemos observar que em todas as etapas do planejamento a definição é do pesquisador, e suas escolhas serão baseadas em seus conhecimentos, crenças, necessidades e objetivos. Não é possível pensar em uma neutralidade completa da ciência, pois ela é produzida por cientistas que precisam tomar decisões, fazer escolhas e toda escolha não é neutra.
Porem, o pesquisador não tem liberdade de fazer o que quiser. Se assim fosse, não existiria uma continuidade do conhecimento. Não seria possível aproveitar de um trabalho anterior, pois esse conhecimento seria fruto apenas de uma pessoa e serviria apenas para o seu mundo. O processo de conhecimento é sobre algo(objeto) e visa ser aproveitado. Sendo assim a descrição do objeto, mesmo que seja totalmente subjetiva, precisa ser clara e o mais próxima da realidade. Quais aspectos foram considerados e quais não foram considerados? Quais cientistas também tem a mesma visão sobre esse fenômeno? E quais observam de forma diferente? A base teórica, os objetivos, o pesquisador, a época e outras variáveis precisam ser claras para compreender a base empírica e as conclusões de um trabalho científico.
A não neutralidade da ciência colocada por Tomanik não diminui a sua importância na aquisição do conhecimento sobre a realidade, apenas nos demonstra que não podemos considerar apenas esse conhecimento como verdade absoluta. Todo conhecimento produzido tem seus limites e seus campos de observação, compreender esses limites faz parte do processo de compreensão e produção do conhecimento científico.
TOMANIK, Eduardo Augusto. O olhar no espelho: “conversas” sobre a pesquisa em Ciências Sociais. Maringá: Eduem, 2004.
sexta-feira, 27 de agosto de 2010
Relatório sobre coleta e analise de dados

Durante a matéria de metodologia em Ciência da Informação fizemos uma comparação de vários autores que tratam da analise e coleta de dados em pesquisa. Autores como Braga, Cervo, Eco, Gil, koche, Marconi, Lakatos, Minayo, Rapazzo e Tomanik tratam dos temas em seus livros e manuais. O grupo fez uma reflexão sobre as diferenças encontradas em cada autor. O trabalho pode ser encontrado aqui.
quinta-feira, 12 de agosto de 2010
O Banner

Experiência muito válida a produção de um banner. Sistematizar as informações da pesquisa é pensar, refletir, reorganizar e analisar a própria. Ou seja, fazer um banner de uma pesquisa faz parte da pesquisa.
Na ciência não basta ser pesquisador, tem que participar..
quinta-feira, 22 de julho de 2010
Nuvem de palavras..

O uso de palavras para representar conhecimento ou informação é um processo natural do homem. Para se comunicar as pessoas pensam, utilizam algumas palavras para representar o que estão pensando e transmitem essas palavras de forma escrita, verbal ou usando sinais para quem se quer comunicar. Quem recebe essas palavras retira a informação dessa representação e compreende o que o outro estava pensando. Nesse processo existem vários problemas de representação fazendo com que o outro não compreenda corretamente o que se quer transmitir e, em alguns casos, quem esta comunicando também não consegue expressar fielmente em palavras o que esta pensando. É um desafio, portanto, retirar conhecimento de textos escritos em linguagem natural. A ciência da informação pode contribuir com esse processo e vários estudos estão sendo feitos nesse sentido.
O site http://www.wordle.net propõem a criação de uma nuvem de palavras a partir de um texto ou de um endereço de blog. Ele utiliza algumas técnicas de processamento de linguagem natural e cria uma expressão visual das palavras do texto, onde o número de ocorrência dos termos no texto analisado sinaliza o tamanho do termo na nuvem. É possível mudar cor, retirar termos, mudar fontes para tornar a nuvem ao seu gosto. Fiz um teste com esse blog e a nuvem gerada é essa acima. Acho que esta bem representativa.
Faça com o seu blog e veja se os termos que esta usando estão refletindo o objetivo principal do blog.
Um abraço,
Duarte.
quarta-feira, 21 de julho de 2010
To ouvindo..

Agradeço os comentários já postados e convido a todos a participarem da avaliação do blog. Contribuam..
quinta-feira, 24 de junho de 2010

quinta-feira, 20 de maio de 2010

sexta-feira, 19 de março de 2010
Pré-projeto de pesquisa
Resumo
Esta pesquisa aborda a aplicação da técnica de Descoberta de Conhecimento em Textos (DCT), com recursos avançados de Processamento de Linguagem Natural (PLN). Seu objetivo é verificar a eficiência do processo de DCT com uso de métodos linguísticos e não só estatísticos. O estudo propõe identificar automaticamente estruturas com potencial de descrever o conhecimento contido no texto, classificá-las morfologicamente, reorganizá-las, para, enfim, executar procedimento de efetiva descoberta de conhecimento.
Identificação do Problema
Estima-se que 80% das informações de uma empresa estão armazenadas em formato textual, informações essas que frequentemente não são percebidas, manipuladas e utilizadas como um potencial produto organizacional das instituições. O volume enorme de dados gerados e a dificuldade de recuperação da informação contida nos textos são os fatores principais para o abandono, com o passar do tempo, do conhecimento registrado em texto.
A descoberta de conhecimento em texto (DCT) surge como uma forma de resolver essa questão, porem o uso de métodos simplesmente quantitativos no pré processamento dos dados gera resultados insatisfatórios devido a inúmeros problemas linguísticos não tratados de forma automática.
Objetivo
Propor uma metodologia de Processamento de Linguagem Natural para uso na Descoberta de Conhecimento em Texto visando solucionar problemas lingüísticos ocorridos em processamento automático de textos em língua portuguesa com o uso de métodos simplesmente estatísticos, aumentando a precisão e eficiência na descoberta de conhecimento contido em dados não estruturados.
Objetivo específico
• Testar a eficácia do uso de técnicas avançadas de PLN aplicada em DCT em comparação com a utilização de métodos convencionais.
• Extrair conhecimento da base textual com aplicação da DCT e PLN e identificar padrões e relacionamentos dos dados descritos com base no conteúdo dos textos analisados.
• Criar classificação automática dos textos através da DCT.
Apresentação
Me chamo Carlos Duarte ou simplesmente Duarte. Sou aluno do Professor Andre Porto na disciplina Metodologia em Ciência da Informação, blog http://metodologiaci.blogspot.com/. Essa pesquisa é na linha Representação e Organização da Informação e do Conhecimento.
Esta pesquisa aborda a aplicação da técnica de Descoberta de Conhecimento em Textos (DCT), com recursos avançados de Processamento de Linguagem Natural (PLN). Seu objetivo é verificar a eficiência do processo de DCT com uso de métodos linguísticos e não só estatísticos. O estudo propõe identificar automaticamente estruturas com potencial de descrever o conhecimento contido no texto, classificá-las morfologicamente, reorganizá-las, para, enfim, executar procedimento de efetiva descoberta de conhecimento.
Identificação do Problema
Estima-se que 80% das informações de uma empresa estão armazenadas em formato textual, informações essas que frequentemente não são percebidas, manipuladas e utilizadas como um potencial produto organizacional das instituições. O volume enorme de dados gerados e a dificuldade de recuperação da informação contida nos textos são os fatores principais para o abandono, com o passar do tempo, do conhecimento registrado em texto.
A descoberta de conhecimento em texto (DCT) surge como uma forma de resolver essa questão, porem o uso de métodos simplesmente quantitativos no pré processamento dos dados gera resultados insatisfatórios devido a inúmeros problemas linguísticos não tratados de forma automática.
Objetivo
Propor uma metodologia de Processamento de Linguagem Natural para uso na Descoberta de Conhecimento em Texto visando solucionar problemas lingüísticos ocorridos em processamento automático de textos em língua portuguesa com o uso de métodos simplesmente estatísticos, aumentando a precisão e eficiência na descoberta de conhecimento contido em dados não estruturados.
Objetivo específico
• Testar a eficácia do uso de técnicas avançadas de PLN aplicada em DCT em comparação com a utilização de métodos convencionais.
• Extrair conhecimento da base textual com aplicação da DCT e PLN e identificar padrões e relacionamentos dos dados descritos com base no conteúdo dos textos analisados.
• Criar classificação automática dos textos através da DCT.
Apresentação
Me chamo Carlos Duarte ou simplesmente Duarte. Sou aluno do Professor Andre Porto na disciplina Metodologia em Ciência da Informação, blog http://metodologiaci.blogspot.com/. Essa pesquisa é na linha Representação e Organização da Informação e do Conhecimento.
Assinar:
Postagens (Atom)